A matter of logs
Logs are very important part of any serious software system. They provide invaluable insight in the current and past state of the system. Simply saving them to a disk or persisting them in any other crude way might probably deprive you from discovering anything interesting in it. The purpose of this article was to describe one such offline processing logs collection system I created years ago and to sketch possible real-time solutions using technologies available today.
Problem description and motivation
The story begins a couple of years ago when I was working on some server-side code that needed to process on a number of logs streaming from the desktop app. These logs contained various time-stamped events and, since at the time I was using Heroku to run web services, I had to be extra careful about the running costs. I also didn’t want to spend too much time on administration of some server software running on EC2 instances. Luckily, business requirements at the time didn’t call for the realtime solution, so in the end I decided to go with the offline one.
Simple(db) solution
Since there were a number of users running the desktop app concurrently, a relatively large number of events were generated, something close to 5K per second. From my experience, that number of concurrent calls on an HTTP endpoint wouldn’t even work on Heroku (for comparison, StackOverflow had around 3000 req/s in 2014). Since this was a desktop app, the decision was made to directly upload compressed batches of events (serialized as JSON data) to S3. When upload of a single batch was finished, app would still call Heroku web service to store a timestamp and a pointer to uploaded S3 file to a SimpleDb. Batching helped cutting down requests to less than 100 per second and writing metadata to SimpleDb was made out-of-band with a help of queue and some background workers. This solution was in the end still calling web service hosted on Heroku, but it was much a leaner one than it could have been.
At a time new-object-created event wasn’t available on S3 and even DynamoDB wasn’t there. SimpleDb was the only hosted columnar data store, with a very reasonable price-tag and bearable constraints for the offline processing purpose. If there was such S3 event, we could have skipped Heroku completely.
Next thing that needed to be done was offline processing of those events. For this purpose I created a daily cron job (running at night though) that was spawning some Ruby code. First it queried SimpleDb by grouping events by timestamp for the previous day. Then it pushed those events to the SQS instance served my the arbitrary large set of listeners. Listeners were pulling related blobs of data from S3, doing some transformations and finally updating various counters in MySQL.
Here’s a diagram of the whole scaffolding:
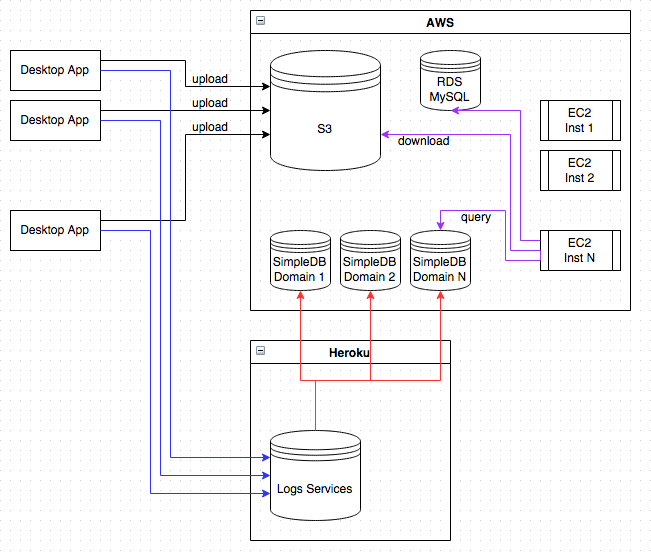
I hope I managed to clearly describe how the previous system was created. Now I am fast forwarding to see how could I build a similar, real-time system with the current technologies.
Fast forward today
Every such journey should starts with a little research. You don’t want to be a system architect stuck with a hammer and a saw; you better upgrade your toolbelt occasionally. After a relatively short research on the subject, I was amazed how enormous real-time logs/events processing area was and how many software products existed in this space. And by products I don’t mean the traditional ones like rsync or syslog based rsyslog or syslog-ng. I confess, it took me more than a day to grasp all the existing software products, what they actually represented and how they fitted inside their respective puzzles.
Producers
If I want to handle my logs in real-time, I obviously have to forget about uploading of compressed batches to S3 and all that offline processing.
I learned that I don’t deal with logs, but events, and the thing I would be doing is real-time events ingestion and processing. One useful acronym is ETL which stands for extract, transform and load, a typical thing which event consumers do.
We are dealing with roughly 5K events per second, so what comes to mind is that desktop apps could push events to some messaging i.e. queueing system. The usual suspects are RabbitMQ, 0MQ, Redis etc. They all could handle that much traffic, without even a blink, and if we needed more, we could always put some reverse proxy in front and happily continue. I would personally go with Redis since it’s very easy to configure and there’s a brilliant reverse proxy twemproxy (aka nutcracker) that supports Redis protocol, that is if I ever needed to create Redis cluster. Reasoning behind such messaging systems is to isolate message producers (in our case desktop apps) from message consumers (our Ruby scripts running on EC2 instances). I previously used highly available S3 service and SimpleDB service (unfortunately, not so highly available) to achieve a similar sort of isolation.
But I discovered there are even cooler toys out there called Apache Kafka and Amazon Kinesis. The main difference between Kafka/Kinesis and those more traditional messaging systems, according to their documentation, is that they are built from the ground up with a distribution in mind. This usually means seamless horizontal scaling with much higher loads.
It seems that Kinesis is less flexible than Kafka, but Kinesis has some other advantages that matter to me even more. If I wanted to have highly-available Kafka cluster, I would need to maintain a number of EC2 instances running Kafka and a separate Zookeeper instance used by Kafka for coordination among the nodes. With Kinesis I don’t need to worry about any of that cluster maintenance. It can even endlessly scale with almost no administrative burden. So I am perfectly happy to continue with the hassle-free Kinesis and write events directly from the desktop app to the Kinesis stream.
Consumers
Second part of the equation is consumption of those messages. I need to ingest each message, transform it a bit and then store it somewhere safe for later access. If data represents some counter, I might update its value in the database, and if it’s some text and I need to search on it later, I could store it to ElasticSearch. As I said, previously I used some Ruby script which execution was triggered once a day by a cron job. I could use that same Ruby script here as well, but this time it wouldn’t be started from a cron job, but from some other code listening to events arriving from the Kinesis stream. Amazon even provides a server implementation that works on top of Kinesis Client Library called MultiLangDaemon and that simplifies development of Kinesis record processors in languages other than Java. But I have my eyes set on something else.
As with messaging products, there are a number of choices in the logs/events collectors/processors arena. At least enough to spin my head once more - Apache Storm, Flume, logstash, fluentd, Amazon Lambda etc. Although these products differ in many ways, for the purpose of what I’m trying to achieve and in what they’re similar, I could use any of them. Apache Storm seems to be very powerful and quite a bit supported by the Amazon. On the other hand, there’s a brand new Amazon offering called Amazon Lambda, the holy grail of no-hassle solutions (which I always preferred, being a developer first person). Lambdas would even relieve me of having EC2 instances for events processing. So all I need to do is rewrite my Ruby transformations into JavaScript (Amazon uses Node.js behind the curtains) and unleash the magical power of Lambda. Sweet!
Cost estimate
It seems that I managed to put all those different pieces together and to at least imagine how would I turn my offline events processing into a real-time analytics solution. And all that using Amazon’s hosted solutions. The only remaining thing to do is to get the rough estimate of costs. I figured I would calculate only how much would I pay monthly for the use of Kinesis and Lambda. My original ETL code was transferring data to MySQL (RDS) and S3 in the “L” phase of ETL. This is something I would still be doing with Kinesis/Lambda solution. The only saving I would be able to achieve is the removal of $500/month worth of EC2 instances crunching the events, now replaced with Lambda.
Kinesis shard-hour cost
I already said that every second we produce around 5K events. Each such event contains around 1K in payload which makes 5 MB/s of data input. Since one shard in Kinesis stream has capacity of 1 MB/s, I would need 5 such shards. This is roughly $55.80 per month.
Kinesis PUT record cost
Next cost is related to PUT records. Number of events per month is 5000 * 60 * 60 * 24 * 31 i.e. 13,392,000,000. Million PUT records costs $0.028, so we end up with additional $375 per month. Since Kinesis messages can hold up to 50K in size, we might once again batch our events and write e.g. 10 events at once. This would make the number of PUT records 500 per second and we would still have system behaving as a real-time. So instead of adding $375, we would have extra $37.5 per month. Notice that the cost of shard-hour hasn’t changed with batching.
Lambda requests count cost
Since I decided to batch the events, I ended up with 1,339,200,000 lambda requests. First 1,000,000 requests are free and each next million costs $0.20. Add another $268.
Lambda duration cost
Now things become a little bit harder regarding the cost estimation. I would need to know upfront how much memory my code would be needing on Lambda and how long would it execute. This all is, of course, impossible without really trying it out. Arriving at this point also makes painfully obvious that I’ll still need to pay what I thought I saved by batching those events. I will make here a really modest estimates and suppose I would need only 128 MB of memory (the cheapest Amazon Lambda tier) and that my code would need 150 ms to process each single event i.e. 1.5 seconds for the whole batch. This makes a total of 2,008,480,000 seconds of work per month (first 3,200,000 seconds are free). Since the price per 100 ms is $0.000000208, we end up with $4178 of additional monthly cost. Oops.
Kinesis/Lambda costs recap
Cost of $100 per month for Kinesis turned out to be a real bargain. It saves me from having at least two nodes Redis cluster and an extra reverse proxy instance, and all that to achieve at least modestly comparable HA properties of Kinesis. Lambda, however, turned out to be too pricey for my budget, even when I was estimating with the cheapest tier.
Summary
To recap, I would be definitely pushing my data to Amazon Kinesis stream, but instead of Lambda I would be running e.g. a single c4.2xlarge instance ($345 monthly cost) with MultiLangDaemon and my slightly modified Ruby code. My guess is that this single machine would be able to process all 5 shards concurrently.
New solution managed to replace storing data to S3 and to remove most of the offline logs-processing EC2 instances, and with the costs remaining roughly the same. And yes, I managed to replace my poxy 24-hours-later analytics with a realtime solution. How cool is that?!
It seems that there are some new and shiny toys to play with on AWS. And once again, they come to rescue from the gruesome maintenance tasks of running software on EC2s, at least for the average back-end developer. But not all of them are for everyone and there is a hefty price tag attached to that Unbearable Lightness of Lambda.
An honorable mention to ElasticSearch ELK stack
Although I love ElasticSearch and its whole ELK stack, logstash (which is btw. the “L” in the ELK and a very, very cool product in its own right) would be more appropriate to use when we would be dealing with the raw logs instead of events. In order to use logstash I would need to write a plugin to deal with events sent by the desktop apps (some boilerplate plus the existing Ruby code). This all seems like an overkill compared to Amazon’s solution. In any other case where I would need to ingest more structured logs (like stuff coming from web servers), make them available for full-text search and even visualise, logstash is the way to go (make sure to check Jordan Sissel’s video).